Zurich Corpora of Slavic (and other) Varieties (ZuCoSlaV)
A major area of ongoing linguistic research at the Slavic seminar includes non-standardised varieties. This also involves the development of annotated linguistic corpora, with a particular focus on dialectal and historical collections and spoken language corpora. The current selection of corpora is available on https://gitlab.uzh.ch/uzh-slavic-corpora
Macedonian Spoken Corpus
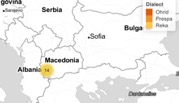
The corpus comprises transcriptions of audio files collected in a series of field research trips in the Prespa, Bitola and Debar regions in 2012, 2014, 2016 and 2019.
Corpus platform: https://escher.pythonanywhere.com/#about
Contact: Anastasia Escher
Pre-Standardized Balkan Slavic Literature

The corpus includes various Balkan Slavic texts from the 15th-19th century. The annotated section includes 20 shorter texts with full morphological and syntactic annotation (48k tokens). The raw section contains 14 sources digitized manually or automatically as a whole (ca. 1M tokens).
Contact: Ivan Šimko
Torlak
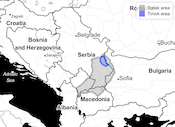
The corpus contains transcripts of interviews about traditional culture and history with speakers of Torlak from the Timok area. It comprises 500,697 tokens representing 80 h of recording.
Search the corpus in NoSketch Engine and KonText
Contact: Teodora Vuković
Serbian Forms of Address

The corpus contains transcripts of interviews about forms of address that Serbian speakers use in colloquial and formal settings. It consists of 171,552 tokens, corresponding to about 19 h of recording.
Go to transcripts (html): https://zislavlingstaticweb02.uzh.ch/sfa/
Search the corpus in NoSketch Engine and KonText.
Contact: Dolores Lemmenmeier-Batinić, Sonja Ulrich
Map Task Corpus of heritage BCMS
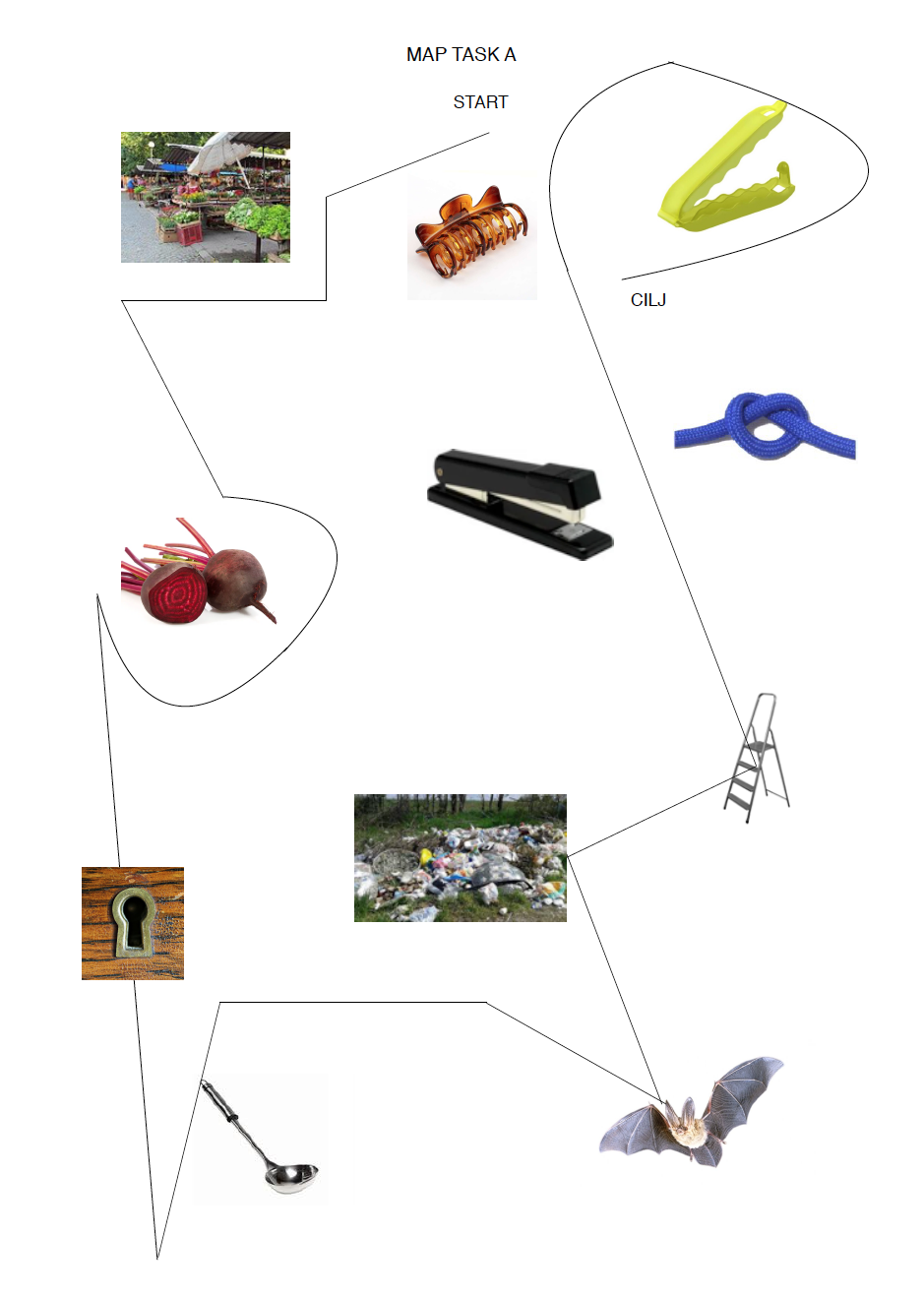
The corpus consists of 30 short transcripts of elicited map task conversations between heritage speakers of BCMS living in German-speaking Switzerland. The corpus is searchable on an interactive platform that supports various types of annotation and metadata querying, as well as custom annotations.
Corpus platform: https://maptask.slav.uzh.ch/
Search the corpus in NoSketch Engine and KonText
Contact: Dolores Lemmenmeier-Batinić
Gheg Albanian Pear Stories

The corpus contains renarrations of Wallace Chafe's Pear Stories video (pearstories.org) by heritage speakers of Gheg Albanian living in Switzerland and speakers from Prishtina. The corpus is currently available as a Universal Dependency (UD) treebank.
Contact: Barbara Sonnenhauser